
為什麼大家都在討論 DeepSeek?
最近,AI 圈裡有個超夯的名字叫 DeepSeek。它是一種新型的「大型語言模型」(LLM),大家可能會好奇:
「現在不是已經有好多厲害的 AI 大模型了嗎?DeepSeek 有什麼特別?」
簡單來說,DeepSeek 重新定義了大模型的訓練方式,讓模型用更少的資源就能達到更強的推理和解題能力。這在過去是很難想像的,因為我們常常覺得 AI 越厲害,就一定得用越多的算力、卡數(顯示卡)和數據去「餵」它。可是 DeepSeek 的重點影響在於告訴我們:或許有別的捷徑。許多開發者急切地想要使用或改進 DeepSeek 的模型上工作或合作。這從相關 GitHub 迅速增加的 Forks、Stars 及貢獻中可以看出。
關鍵:只看「結果」也能讓 AI 學會複雜推理
以往,人們覺得 AI 在學習過程中,需要給它很多中間步驟的指導或「過程獎勵」(例如:完成每一步要給它小小的獎勵,這方式叫做「過程獎勵模型 (Process Reward Model, PRM)」)。但 DeepSeek 的做法很不一樣——只要透過「最終結果獎勵 (Outcome Reward Reinforcement Learning, OR-RL)」。
具體來說,就是在訓練時,不再針對每一步驟詳細人工指導,而是單純看輸出結果對不對。如果對了,就給模型正面獎勵;如果錯了,就給它負面獎勵。即使沒有特別標註中間的思考過程,模型依舊能自行摸索,進而達到類似「思考—自我檢查—糾錯」的複雜行為。
純粹看「最終的結果」對不對,再決定要不要給獎勵;這種「純粹結果獎勵 (Pure Outcome-based RL)」方法,成功挑戰了過去「必須依賴 PRM」的傳統觀點。相對的,也質疑了人工標註在訓練模型上的效果。
不需要特別人工標註中間的思考過程。DeepSeek 利用這套思路,展現了高水準的推理能力,甚至在某些任務上比需要大量中間監控的傳統方法更有效率。
因此,只看「結果」不看「過程」,不僅可以大幅降低在標註中間思路上的成本,也讓 AI 更能展現出「自學、自我糾錯」的潛力,進一步為整個 AI 產業帶來一股新的訓練風潮。令人驚訝的是,這樣的方式居然能幫助模型養成「長鏈推理 (Chain-of-Thought, CoT)」和「自我糾錯」的能力,甚至在某些任務上表現和需要大量標註的傳統方法不相上下,甚至更好。當然,有許多更值得討論的技術細節,我在文末再多做補充。
為什麼這件事這麼重要?
DeepSeek app sitting at number 1 overall in the US Iphone App Store is not on my bingo card and is the biggest sign yet that the ChatGPT moat can maybe be cracked. pic.twitter.com/ffoqpk8Tlh
— Nathan Lambert (@natolambert) January 26, 2025
翻轉「大模型就是燒錢」的印象:過去一提到「AI 大模型」,大家腦中就浮現「超大資料中心」「堆算力」「天價經費」。DeepSeek 的方法算是打破這種刻板印象:不一定要砸錢堆算力,也能衝出好成績。這很可能在未來吸引更多中小型企業或團隊嘗試投入 AI 研發,進一步活絡整個生態系。
打破「過程獎勵」的迷思:以前,幾乎所有大模型團隊都覺得要讓 AI 真正理解「怎麼做」,就必須在過程中給它很多提示或獎勵。可 DeepSeek 卻告訴大家,「或許不用那麼複雜,只看最終成果就好」,也能讓 AI 學到強大的推理能力。
這讓很多正在研發 AI 的工程師或科學家開始想:「是不是該調整一下我們的訓練方式?」
大幅節省硬體成本:傳統模式下,訓練一個超大型 AI 模型往往需要堆超多顯示卡(GPU),而且通常都以 NVIDIA 的卡為主。這對很多新創公司或研究團隊來說,是一個非常高的門檻。但 DeepSeek 的方法證明,只用比較少的 GPU 或者使用 AMD 的卡,都有機會達到不錯的效果。對業界來說,這等於「開了一扇新門」:不用再花天價買特定廠牌的卡,也能做出超厲害的 AI。
對 AI 產業未來可能帶來什麼改變?
推動 AGI (Artificial General Intelligence) 的發展:DeepSeek 展現出一種「自我反思、自我糾錯」的能力,而這恰恰是邁向通用人工智慧(AGI)的重要一步。雖然還有很長的路要走,但這次的突破給了研究者更多信心。
技術壁壘降低,競爭更激烈:有了更省算力的方法,小公司跟團隊的投入門檻降低,市場上就不會只剩下少數巨頭壟斷 AI 技術。這對一般用戶或產業來說是好事:競爭激烈,才有更多新功能或更便宜的服務出現。
更多團隊重新思考訓練策略:DeepSeek 的成果非常亮眼,因此各大 AI 實驗室和公司可能都會想:「我們是不是也能用這種方式來訓練?」這股「跟進潮」能帶來不少技術上的創新,未來或許會出現更多透過純粹結果獎勵訓練出的模型。
衝擊似乎才剛剛開始
之所以引發如此大的關注,並不是只有在「省錢」方面的意義,更重要的是它告訴了我們一條不走傳統老路,卻依然能讓 AI 持續成長的新方法。這次的成果不只能讓大模型變得「更強」與「更省」,也可能讓更多玩家加入 AI 的研發行列。可以想見,接下來市場上會湧現各式各樣基於 DeepSeek 創新思路的模型和應用,進一步刷新 AI 生態。
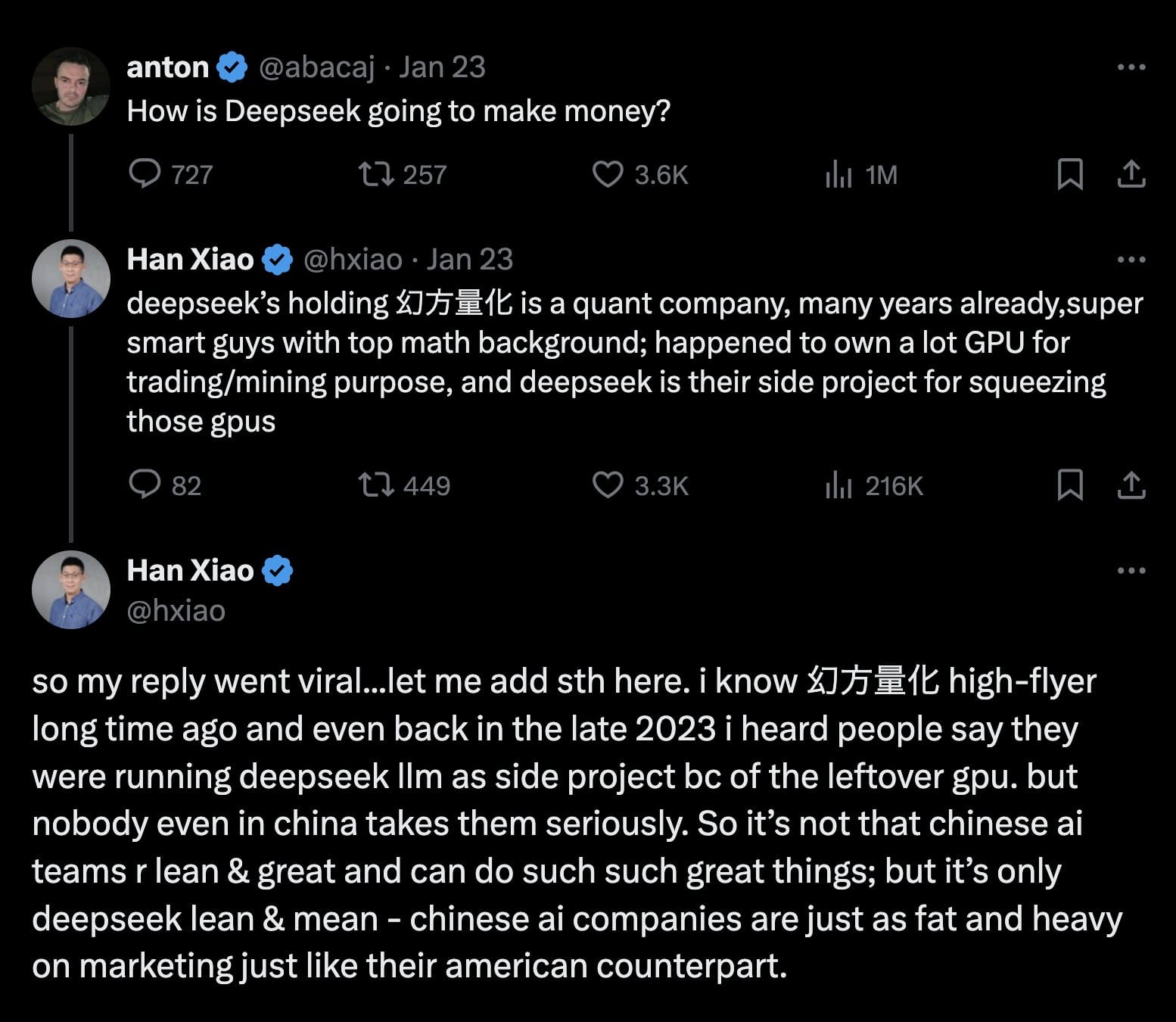
DeepSeek 從哪裡來?
幻方量化原本就是一家以量化金融為主業的公司,因為手頭上擁有一批「暫時用不到的 GPU」,才意外催生了 DeepSeek 這樣的「side project」。然而,這個看似非主打的計畫卻在 AI 大模型領域取得了突破性的進展,也再度印證了靈活運用資源與大膽嘗試在技術創新中的重要性。對 AI 行業來說,DeepSeek 的成功既顯示了「新方法帶來新潛力」,也展示了小團隊依然可能做出驚人貢獻的典範。
科技大老怎麼評論
首當其衝,Sam Altman 表達了 deepseek R1 是一個非常令人印象深刻的模型:
deepseek's r1 is an impressive model, particularly around what they're able to deliver for the price.
— Sam Altman (@sama) January 28, 2025
we will obviously deliver much better models and also it's legit invigorating to have a new competitor! we will pull up some releases.
Marc Andreessen 在其 Blog 和訪談中公開討論了 DeepSeek 如何可能改變 AI 開發的範式。他強調 DeepSeek 的成功可能鼓勵更多開源計劃,從而可能導致一個更民主化的 AI 開發環境,在這裡創新不僅限於少數大型公司。
Deepseek R1 is one of the most amazing and impressive breakthroughs I’ve ever seen — and as open source, a profound gift to the world. 🤖🫡
— Marc Andreessen 🇺🇸 (@pmarca) January 24, 2025
Mark Zuckerberg 也承認了 DeepSeek 的是個好的模型:
稱 Deepseek 是 "Great Chinese model "
微軟 CEO Satya Nadella 在達沃斯世界經濟論壇上稱讚了 DeepSeek 新模型:

開源 vs. 封閉式模型
不少大佬討論的焦點,轉向了開源 AI 與專有模型的優點。DeepSeek 的模型,作為開源且仍然具有競爭力,重新引發了關於封閉式的專有秘密的價值與開源開發的合作好處的辯論。就像主導 Meta AI 研究的首席科學家楊立昆 Yann LeCun 的觀點,對於那些看到 DeepSeek 的表現後認為:「中國在 AI 領域已經超越美國」的人們,你們誤讀了這一情況。正確的解讀應該是:「開源模型正在超越專有模型」。DeepSeek 從開放研究和開源(例如來自Meta 的 PyTorch 和 Llama)中受益。他們提出了新的想法,並在其他人工作的基礎上進一步發展。因為他們的工作是公開和開源的,所以每個人都可以從中受益。這就是開放研究和開源的力量所在。
open source everything
— jack (@jack) January 27, 2025
在 X(前稱Twitter)、LinkedIn 和技術專注的論壇如 Hacker News 上的討論中,技術愛好者和專業人士爭論 DeepSeek 的模型可能導致更快的創新週期,使更多人能夠接觸到最先進和更便宜的 AI(包含產品服務和 API),但也引發了關於安全性和 AI 的道德使用問題的關注。
技術亮點與參考價值
雖然中國有傳出某些大摩習是套殼或蒸餾的,但 DeepSeek 不是,而是在 Transformer 基礎上進行了創新,包括混合專家模型(MoE)、多頭潛注意力(MLA)、多令牌預測(MTP)、長鏈式推理(CoT)等,還進行了強化學習(RL)的訓練,尤其以 RL vs RLHF 的比較,這段在社群有很大的討論度,文後也多補充這段的討論,這些相信對於封閉模型也有非常大的參考價值。
- Mixture of Experts (MoE):通過自然負載均衡和共享專家機制來平衡專家工作量。
- Multi-Head Latent Attention (MLA):減少了記憶體和計算開銷,提升了推理效率。使用了潛向量 (latent variables) 來動態調整注意力機制,在訓練中減少 RAM 跟算力的需求,也在推理中降低了緩存的佔用空間。
- Multi-Token Prediction (MTP):提高了特定場景下的效率。能減少一些重復中間步驟,如數學和代碼生成上能提高效率。
- Chain of thought (CoT):通過長鏈推理能力提高了模型的推理步驟清晰度,並且在此過程中觀察到了模型的反思、多路徑推理、頓悟時刻時刻 (突破瓶頸的 aha moment) 等自發行為。
- RL (和 SFT):探索了不依賴人類標註數據的微調方法。不依賴人類標注數據微調、自主推演的能力,打開了新的思路。
- 高質量的合成數據:在必要時,只進行人工後處理。參考 DeepMind 的 Research Scientist 說法。
I read the DeepSeek-R1 paper the day it came out, and I don’t think GRPO is the key to its success. Instead, here’s what truly matters (ranked by importance):
— Jiao Sun (@sunjiao123sun_) January 28, 2025
1. Iterative RL and SFT
2. A hybrid reward model—mixing rule-based RM and neural RM for deterministic tasks
3.…
討論:強化學習(RL) vs. 人類反饋的強化學習 (RLHF)
Andrej Karpathy 甚至認為 RLHF 不是 RL,因為模型的認知與人類標注者的認知不同。人類永遠無法準確標註這些解決策略及其應有的樣子。它們必須在強化學習中被發現,以便在經驗和統計上對最終結果產生有益影響。他舉例在兒童學習與深度學習中,都存在兩大主要學習型態:
- 模仿學習(imitation learning):觀看並重複(例如預訓練、監督式微調)
- 嘗試—錯誤學習(trial-and-error learning,也就是強化學習 RL)
而他最喜歡的簡單案例就是 AlphaGo 有兩種模式:
[1] 是透過模仿專家棋手來學習下棋。
[2] 則是用強化學習來贏得比賽。
幾乎每個像魔法一樣的成果,都來自 [2]。[2] 的力量遠遠高於想像。[2] 就是為什麼 AlphaGo 能擊敗李世乭。[2] 也是所謂的「頓悟時刻 (aha moment)」,讓 DeepSeek 或 o1 發現「去重新評估假設、回溯、嘗試別種作法」之類的有效性。你可以在模型的 推理過程中看到它如何反覆思考。這些想法是湧現的(!!!),而且這真的是非常厲害、令人印象深刻,而且是新的。模型若只用 [1] (模仿學習)」是永遠學不到這些的,因為模型和人類標註者的思維模式不同,人類根本無法精確標註出這些解題策略該如何呈現。
I don't have too too much to add on top of this earlier post on V3 and I think it applies to R1 too (which is the more recent, thinking equivalent).
— Andrej Karpathy (@karpathy) January 27, 2025
I will say that Deep Learning has a legendary ravenous appetite for compute, like no other algorithm that has ever been developed… https://t.co/mX5kiQEJPX
結論:強化學習(RL)是強大的,但基於人類反饋的強化學習(RLHF)並不是,DeepSeek 的模型驗證了這點。
個人觀點
- 對算力的需求不可能下降:隨著效率提高,雖然成本可能下降了,但因為便宜會讓應用變得更普及,導致總消費量和應用會是上升的。
- 算力可能還是最終關鍵:OpenAI 的發展路徑是很簡單粗暴的,也不排除算力到了一定的量,又會發生新的質變,屆時封閉模型又將拉開差距。
- 算力可能比數據重要的很多。合成資料(synthetic data)生成與強化學習相關聯,暗示數據,傳統上被視為獨立的,其實也是計算努力的產物。
- 這次透過 DeepSeek 的開源,技術社群討論了兩種學習類型:模仿學習,涉及有監督的微調,以及通過強化學習進行的試錯學習,後者顯著更強大,並且是深度學習驚人成就的源頭。
- 短期內衝擊到的會是目前花錢使用 OpenAI API的應用廠商,因為私有部署的成本不高,也勢必讓 OpenAI 針對個模型降價或開放免費使用,這導致 AI 應用更能百花齊放,降低成本造成的後顧之憂。
如果你也對 AI 大模型感興趣,或正在思考如何降低 AI 研發門檻、提高模型能力,那麼 DeepSeek 絕對值得你持續關注。畢竟,在這個 AI 技術蓬勃發展的時代,任何創新都可能是通往下一個時代的關鍵!
本文參考眾多資訊大多來源於 X / Grok AI / ChatGPT-4o / ChatGPT-o1 潤飾。