
從 Data 如何變成 AI 應用

如果不想整天 Fomo 呼叫最新推出的 API,想靜下來想學點基礎,那你不能錯過從 Data 到 AI 應用的歷程,尤其是訓練與微調的原理。這篇是我邊學邊紀錄的筆記,歡迎分享與指教。
我們天天看到的是 ChatGPT、Claude、Gemini 這些「產品」,它們能和人對話、能幫忙寫程式、甚至能寫詩。但這些產品的真正底層武器,來自於一個個「前訓練好的模型」。
太長不想閱讀,大致上是這樣來的:資料處理 > 前訓練 > 後訓練 > 部署應用。
詳細的步驟如下,資料前置處理:
- 資料收集(Data Collection)
- 資料清理與預處理(Cleaning / Preprocessing)
- 去重與重複內容處理(Deduplication)
- 資料標準化與格式化(Normalization / Formatting)
前訓練:
- 斷詞(Tokenization)
- 混合與資料排序(Data Mixture & Ordering)
- 架構與超參數設計(Architecture & Hyperparameters)
- 前訓練過程(Pre-training Process)
- 驗證與中間評估(Validation / Monitoring)
- 檢查點與版本管理(Checkpointing & Version Control)
後訓練
- 微調階段(Fine-tuning / Instruction Tuning / RLHF 前置)
- 監督式微調(Supervised Fine-Tuning, SFT)
- 指令調整(Instruction-Tuning)
- 建 Reward model(人類偏好模型)
- RLHF/行為對齊(Reinforcement Learning from Human Feedback)
- 驗證與安全(Validation / Alignment / Safety)
部署應用
- 部署與持續調整(Deployment & Continuous Update)
- 推論與監控 (Inference and Monitoring)
前訓練簡介
2025 年的 AI 世界,競賽不再只是誰的模型參數更大、誰的公司市值更高,而是 誰能更快、更便宜、更有效率地打造出下一代基礎模型。這背後的決勝點,正是「前訓練(Pretraining)」這個最不起眼,卻最根本的環節。 ChatGPT、Claude、Gemini 這些「產品」,它們能和人對話、能幫忙寫程式、甚至能寫詩。但這些產品的真正底層武器,就是來自於一個個前訓練好的模型。
如果說後訓練(微調、對齊、人類回饋強化學習)是化妝與服裝設計,讓 AI 看起來像個禮貌得體的助理,那麼前訓練就是骨骼與血肉——沒有這一步,什麼後續打磨都無從談起。
想想近兩年的開源社群。過去我們會直覺認為,只有資本雄厚的巨頭公司才能訓練出足以媲美 GPT-4 等級的模型,因為那需要龐大的算力與經費。但 2024 年之後,現實已經被打破。像 Mistral、LLaMA 社群 這樣的團隊,憑藉更聰明的演算法設計、更嚴謹的資料清洗流程,居然能用相對有限的資源跑出接近閉源巨頭的水準。
這代表什麼?代表競爭的核心已經不只是「錢多就能贏」,而是誰能在 資料、演算法、工程效率 之間找到最佳平衡。真正的突破點在於:如何用更低成本完成高效的前訓練。
Sam Altman 最近在他的「三個觀察」部落格裡說:
AI 成本每 12 個月下降 10 倍。
如果這是真的,那就意味著前訓練會像摩爾定律一樣成為新時代的加速器。這不是誰做得出超越人類的 AI,而是「誰能在最短時間內,用最少資源跑出最強、最適合應用場景的前訓練模型」。
前訓練為何關鍵?
很多人第一次聽到「前訓練」,腦海裡浮現的是「預備動作」或「暖身」。但在 LLM 世界,前訓練不是暖身,而是本體。簡單來說,前訓練就是:把模型丟進海量文字資料裡,要求它不停地預測下一個 Token。
這聽起來好像很笨拙。就像拿一本書給小孩,指著第一句「台灣的首都是」——小孩要猜下一個字。答「高雄」就錯,答「台北」就對。模型就是這樣學習:不斷猜錯、不斷修正,直到它能把語言模式學進腦子裡。
那麼問題來了:為什麼光是「預測下一個 Token」就能養出 ChatGPT 這樣的智慧體?這就像我們人類的語言能力。我們平常講話時,其實腦子裡也在做「下一個字的預測」。如果我說「今天天氣真」,你大腦裡自然會浮現「好」「冷」「熱」等選項。LLM 只是把這種「機率選擇」變成數學。
前訓練就像石油開採。你先把原油抽上來(大規模模型訓練),這時候原油本身不能直接用。你必須經過提煉(微調、對齊),才會變成汽油、塑膠、能源。前訓練模型就是原油,它本身笨拙,但價值無窮。
前訓練資料來源
在 AI 的世界裡,資料就是新石油。這句話在 2020 年前後還只是一句口號,但到了 2025 年,它已經成為產業現實。誰擁有最多、最乾淨、最有結構化的語料,誰就能領先。
1. 資料來源:網路大礦場
大部分前訓練模型的資料來源有兩種:
- 自行爬取網頁:OpenAI、Anthropic 採用的方式。
- 公共數據集:Common Crawl 最有名,自 2007 年以來每個月持續抓網。
Common Crawl 規模之大難以想像。2024 年 4 月的抓取,就包含 27 億個網頁、386 TiB HTML。這就是語言的金礦。
2. 乾淨數據煉金術
HuggingFace 推出的 FineWeb,是一個更透明、可追溯的資料管線。它做了幾件重要的事:
- URL 過濾(先擋掉垃圾站)
- 語言分類(只留英文)
- Gopher 過濾(刪除低品質)
- MinHash 去重(去掉重複)
- PII 移除(保護隱私)
經過這些步驟,原始 數十兆 Token 被壓縮成一個乾淨的 15 兆 Token 語料庫。
這就是 HuggingFace 的策略:讓開源社群能用上透明、可重現的數據。OpenAI 選擇封閉數據,Meta 半開放,HuggingFace 完全透明。這三種策略背後,其實代表三種不同的競爭哲學:
- OpenAI:壟斷數據,打造黑箱優勢。
- Meta:釋放部分能力,讓研究社群推進生態。
- HuggingFace:徹底民主化,把「石油」變成公共財。
語言拆解的藝術
在資料處理之後,模型不能直接「吃」文字,它需要把字拆成「Token」。
1. 為什麼不能直接用字元?
如果每個字都單獨處理,那序列會長到不可思議。舉例來說,一篇新聞文章可能需要幾萬字元,模型處理起來效率低到爆炸。
2. Tokenization 的演進
- BPE(Byte Pair Encoding):從最小單位開始,合併常見字串。
- SentencePiece:Google 提出的更靈活方式,對亞洲語言特別友好。
- TikToken:OpenAI 的 GPT-4 使用的 tokenizer,能更高效拆解空格與詞組。
3. 中文的挑戰
中文沒有明顯的空格,斷詞難度遠高於英文。比如「人工智慧」會被拆成「人工」「智慧」,但在某些情況下,系統會誤拆成「人」「工智」「慧」。這就是中文 LLM 的困境。

Tokenization 就像 DNA 編碼方式。不同的拆解方法,決定了模型學到的「語言基因」。
學習——從簡單到聰明的工程
如果說資料和 Tokenization 是燃料,那神經網路就是學習引擎。沒有它,再多的資料也只是堆在那裡。以下稍微提及神經網路的演進。
一開始,大家用的是 RNN(Recurrent Neural Network,遞迴神經網路)。它的設計很直覺:前一個時間步的輸出會傳到下一個時間步,這樣一來,模型就能「記住」之前的資訊。對於像文字這種序列資料來說,RNN 算是第一代拿來處理的工具。比方說,你餵一句話:「我今天去超市買了⋯」,RNN 在處理到「買了」時,其實腦子裡還留著前面「超市」這個資訊,所以它可能猜下一個字是「東西」或「水果」。這在短序列裡很好用。
問題來了——RNN 的記性很差。因為它的記憶會隨著時間步驟傳遞,不斷被「稀釋」掉。就像玩傳話遊戲,訊息傳到第 10 個人就開始變形,傳到第 100 個人基本上完全變樣。這在數學上叫「梯度消失」或「梯度爆炸」問題。結果就是:前面說過的重要內容,走到後面模型幾乎記不得。就像你讀小說讀到第 200 頁,卻忘了第 1 頁角色的名字。
為了解決這個痛點,研究者想出了 LSTM(Long Short-Term Memory,長短期記憶網路)。顧名思義,它的目標就是讓模型能同時處理「短期記憶」和「長期記憶」。它加了三個「閘門」(Gate):輸入閘、遺忘閘、輸出閘,來控制資訊要不要留下、要不要刪掉。想像一下,你的腦子突然有一個「白名單/黑名單系統」。重要的訊息(例如「主角的名字」)會被放到白名單裡牢牢保存,不重要的(例如「天空是藍的」)就被遺忘閘刪掉。這樣一來,LSTM 就能在更長的序列裡保留關鍵資訊。後來還有一個變種叫 GRU(Gated Recurrent Unit),可以想成是「精簡版 LSTM」,把一些閘門合併起來,效果相似但運算更快。以上方式都統稱為 RSS 家族。
不過,這些改進還是沒能徹底解決效率問題。以上方法本質上是「逐字處理」的設計,也就是它得一個 token 一個 token 依序讀下去。所以雖然 LSTM 在 2016 年還是 NLP 世界的主力(Google Translate 當年就是靠它支撐),但大家心裡其實都明白:這不是終點,還缺一個更徹底的突破。
研究圈裡那時的氣氛有點像電燈發明前的時代——煤油燈雖然能用,但大家都在暗暗等待一個真正的「質變時刻」。然後,2017 年,這個時刻真的來了⋯⋯
革命的起點
真正改變一切的是 Transformer。2017 年 Google 的一篇論文〈Attention is All You Need〉直接掀起革命。這種架構靠 Self-Attention 機制,一次就能把整段文字的上下文抓進來,而不是一個字一個字往下讀。而且這種方式更容易平行化處理,也導致了 GPU 的需求大大提高。結果就是:不僅更聰明,還更快。這就是為什麼現在幾乎所有 LLM 的底層都是 Transformer。


Scaling Law 的魔力
OpenAI 後來發現一件驚人的規律:模型的表現,跟三個東西呈指數關係——參數數量、資料量、算力。 這個規律被稱為 **Scaling Law。意思是,只要你把模型變大、資料丟更多、GPU 燒更兇,結果就會更好。簡單粗暴,但很有效。
這就是為什麼 GPT-2 只有 15 億參數,GPT-3 就直接拉到 1750 億,整整大了一百倍。當時大家都驚呆了:原來 AI 真的可以靠「肌肉」堆出智慧。
- GPT-2:1.5B 參數,已經能生成看似有邏輯的文字。
- GPT-3:175B 參數,正式進入「可用」的階段。
- GPT-4:具體規模沒公開,外界普遍估計已遠超上一代。
到這裡很容易得出一個直覺:堆就對了。但故事不只如此。
訓練的效率也是決勝點
Scaling Law 告訴我們「往大方向走會變好」,卻沒告訴你代價。現實是:
- 規模越大,算力與成本呈爆炸式上升;
- 不是每家公司都能為了一個實驗,就投入好幾億美元;
- 更別說要持續優化、頻繁迭代。
所以,你能不能用更少的資源,擠出同等甚至更好的效果:
- 誰能把同樣的算力用得更久、更聰明?
- 誰能把有限的資料清得更乾淨、混得更合理?
- 誰能用 MoE、蒸餾、壓縮等技巧,讓小模型發揮大模型的效果?
訓練過程的原理——錯誤中學習
神經網路的學習,其實沒有想像中那麼神祕,本質上就是:不停犯錯 → 修正錯誤 → 慢慢變準。
不斷嘗試錯多少
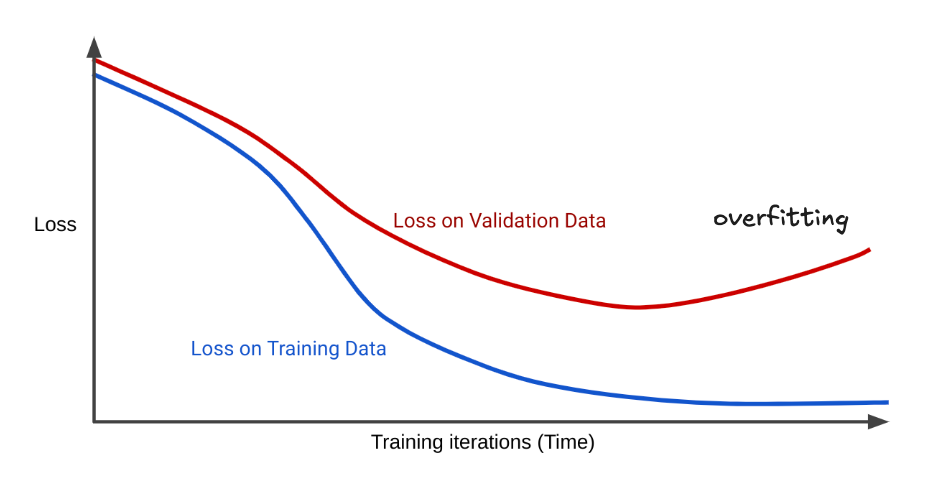
在 AI 的世界裡,錯誤不是單純的「對」或「錯」,而是可以被量化的。最常見的工具叫 Cross-Entropy Loss。簡單理解,它就是拿模型的預測分布,跟正確答案比一比,看差距有多大。
差得越多,Loss 就越高;越接近正確答案,Loss 就越低。這就像考試時,老師不是只打勾或打叉,而是給你 30 分、70 分、90 分,用數字精確描述「差了多少」。
數據調音師
有了錯誤分數之後,模型要做什麼?它會把這個誤差「往回傳」給整個網路,告訴每一層、每個權重:「剛剛這裡出錯了,下次要調整。」這個過程就叫 反向傳播(Backpropagation)。
如果要用一個生活比喻來說,這就像調音。吉他彈起來覺得音不準,你就轉旋鈕,往高了調一點、或往低了調一點。神經網路的每一次更新,其實就是在「調音」,只是它同時有幾十億個旋鈕在動。這就是所謂的「學習」:不是一蹴可幾,而是不停在錯誤中校正方向。
這裡也可以提一下近期的 Andrej Karpathy 最近在 Podcast 裡的觀點(這集甚至連 Elon 和 Marc Andreessen 都有轉發)。
他認為現在的 LLM 雖然強大,但仍有根本性的認知缺陷。一是——它們缺乏持續學習(continual learning)。每次訓練都像一場「重置世界」,學完就凍結,無法像人類一樣隨時從經驗中更新。二是——它們沒有類似海馬體或杏仁核這樣的結構,無法產生情感、本能與動機。他也批評目前業界常用的強化學習(RL)方式,其實像是「透過吸管吸取監督」(sucking supervision through a straw)。模型試了上百種行為,最後只收到一個「對」或「錯」的信號,這不但效率低,也可能誤強化那些「誤打誤撞成功」的錯誤策略。有趣的是,他還說—
人類「記性差」其實是個特點,而不是缺陷。因為忘記細節、保留抽象,迫使我們去看見模式與概念,而不是像 LLM 那樣記下所有 token。
開始使用 AI 模型——推論(Inference)
所謂推論(Inference),簡單來說就是 模型上場表演的階段。前訓練和調參好比是長時間的排練,而推論就是正式演出,觀眾坐滿劇場,燈光打下來,模型要開始輸出文字了。
回到 2019 年,OpenAI 推出 GPT-2。它第一次展現了「電腦能寫出一段看似合理的文章」。對當時的我們來說,這已經是震撼級的突破。它能模仿新聞報導、接著寫小說段落,甚至能生成一篇看起來有板有眼的技術說明。第一次看到的人,心裡的感覺大概是:「哇,這東西會寫作!」
但很快,大家也發現 GPT-2 的限制:
- 上下文太短:它一次最多只能處理 1024 個 Token。換句話說,它的「注意力」非常短暫,就像一個人只能專心聽前後一句話,前面講過的東西全忘光。
- 沒有記憶:你和它聊一聊,換個主題再回來,它完全記不得之前的對話。體驗起來像是「金魚腦」的 AI。
- 偏見與抄襲:因為訓練資料來自網路,它常常會直接「搬運」原文,甚至把網路上的偏見、錯誤一併吐出來。
這些缺點沒有掩蓋 GPT-2 的突破,反而更突顯它的重要性。因為它讓人第一次真正相信:生成式 AI 是可行的。就像第一台能飛上天的飛機,雖然飛得不高、不遠,但它證明了「人類真的能飛」。
後來的進展,幾乎都是在 GPT-2 奠定的基礎上往前走。
- Claude 把上下文拉長,從幾千 Token 拉到上百萬 Token,直接解決了「短注意力」的問題。
- ChatGPT 在 GPT-3 的基礎上加上對話能力,並透過 RLHF 對齊人類意圖,從「文字模擬器」變成「聊天助手」。
- 其他新玩家(像開源社群或新創團隊)則在效率上做文章,證明不一定要花幾十億美元,也能跑出效果不錯的模型。
如果說 GPT-2 是第一個敢踏上舞台、哪怕音準還不穩的歌手,那麼後來的模型就是在它的基礎上,一代比一代唱得更動聽,也知道其他地方要怎麼加強和補足。
後訓練——成為 AI 應用
我們常聽到「基礎模型(Base Model)」,但它其實有點像是 還沒打磨的原石。如:GPT-4-turbo,它的能力來自於大量前訓練,能模擬網路上看到的語言模式,生成一段段文字。可是,這些文字並不一定符合我們的需求。
舉個例子,如果你把 GPT-2 問世時的模型丟到今天的場景裡,你可能會覺得它比較像「網路文章隨機生成器」。它能接著寫下去,但它不懂「這是一個問題」或「你需要一個答案」。換句話說,它只是單純地「模仿網路」,而不是「理解你的意圖」。所以基礎模型本質上就是一個「網路文件模擬器」。厲害歸厲害,但還沒有「對齊人類」。
後訓練的必要性
這時候,後訓練(Post-training)就登場了。它的任務就是把原石打磨成鑽石,讓模型不只會生成文字,還能「照著我們的意思來」。最常見的兩種方法是:
- Instruction Tuning:簡單說,就是用「指令範例」去教模型什麼叫「聽懂指令」。例如,給它大量類似「請翻譯成英文」「請幫我總結」這樣的例子,讓它慢慢學會「遇到這類提示時要乖乖照做」。
- RLHF(Reinforcement Learning with Human Feedback):這更進一步。人類會先評分模型的回答,告訴它「這樣比較好,那樣比較差」。模型就像在玩遊戲一樣,根據人類的「獎勵」調整行為,慢慢變得更合乎人類期待。
沒有這些後訓練,GPT-4 本質上也只是一個龐大的「文字模擬器」,雖然能生成內容,但不一定能符合人類的期待。有了後訓練,它才被打磨成我們今天熟悉的 ChatGPT —— 不只是能聊天,還能解題、做摘要、寫程式,甚至當作工作與生活中的數位助理。就好比一個小孩,光靠模仿大人的說話方式,頂多能把話講得像樣,但不一定能回答問題。只有經過真正的引導和糾正,他才會明白什麼叫「回答問題」,什麼叫「遵循指令」。這就是後訓練存在的必要性。
AI 戰場的第一戰線
在這場 AI 大戰裡,誰能在這裡勝出,後面的產品與生態基本上就佔了先機。
成本戰
第一個戰場就是 成本。現在訓練一個大型模型,動輒要花上數千萬甚至上億美元。問題是,錢燒得快,未必能燒出好結果。這時候就看誰能用「更聰明的方式」壓低成本。
例如,有的團隊選擇更精緻的資料清理管線,把噪音減到最低,讓模型用同樣的算力卻學得更快;有的則透過架構創新,讓小模型能打出大模型的效果。這場比拼,說穿了就是:誰能以更低的 GPU 電費,跑出 State-of-the-Art 的成績。
資料戰
接下來是 資料。一句老話:Garbage in, garbage out。前訓練最依賴的就是語料庫,資料乾不乾淨、規模夠不夠大,直接決定模型的上限。這裡的競爭態勢也很明顯,有些公司靠封閉的專有數據集(像 OpenAI),用「黑箱」維持領先。有些則押寶在開源社群,透過公共數據(像 HuggingFace 的 FineWeb)建立透明優勢。資料不只是量的比拼,更是質的較勁。誰能確保資料合法、去掉偏見、同時保持多樣性,誰就能跑得更穩。
技術戰
第三個戰場是技術創新。這裡的關鍵詞就是:MoE(Mixture of Experts)、蒸餾(Distillation)、壓縮(Compression)。傳統思路是「把模型做大」,但這已經不是唯一答案。像 Mistral 就靠 MoE 模型,把參數分派給不同「專家子網路」,不需要所有參數同時上線,就能保留大模型的效果,同時降低運算成本。這種打法,讓中小公司也有機會挑戰巨頭,而不是只能眼睜睜看著 OpenAI、Google 獨霸市場。
政治戰
最後一個戰場,是 地緣政治。AI 已經不是單純的科技問題,而是國力競爭的一部分。美國和中國,分別代表兩種模式:美國:以 OpenAI、Anthropic、Meta、Google 為主,透過商業與學術的結合領先全球。中國:則有更多國家政策支持與本地巨頭(百度、阿里、智譜等)的推動。
除此之外,還有另一條戰線:開源社群 vs 商業巨頭。開源的代表像 LLaMA、Mistral、HuggingFace 社群,它們用開放的模式快速迭代,形成生態圈。商業巨頭則靠資本與產品化能力,打造閉環服務這場競爭,最終不只是模型誰比較強,而是整個生態與治理方式的對抗。
總結
總之,現在你知道怎麼從大數據中提煉成一個 ChatGPT 了,它就像石油煉製一樣,從收集 Data、提煉、加工、到最後的成品。
前訓練會逐漸變成一條完整的產業鏈。這條鏈條上,每一環都可能誕生一家新的公司或一個新的突破點。未來我們可能會看到「資料清洗公司」「高效 Tokenizer 初創團隊」甚至「專做能源優化的算力供應商」。
另一方面,後訓練(Post-training)也正在變成下一個技術爆點。過去我們只談 SFT、Instruction Tuning、RLHF,但現在業界正在探索更多更新的方式——這些方法的目標,都是讓模型「更懂人」——不只是生成文字,而是能理解語境、做決策、甚至根據不同用戶的偏好自我調整。
前訓練讓模型學會世界的規律,後訓練讓它學會我們的意圖。
而這中間的無數種創新,正是下一波 AI 創業的熱點。
其次,雖然算力還是關鍵,但資料清洗的品質與演算法的效率也會決定差距。就像一個廚師,不是食材越多就一定能做出最好吃的菜,而是看你會不會挑料、會不會煮。這就是為什麼一些資源不算頂尖的團隊,也能跑出接近巨頭的模型。小公司推出的模型雖然參數比 OpenAI 或 Google 的那些旗艦模型小很多,但在某些 benchmark 上表現非常接近。
所以,我們可以這樣總結:你已經知道從 Data 到部署 AI 應用的大致步驟。下一步試著去拆解你想做的,看到的哪一環節有改進空間,以及在你的場景中,哪一部分是最值得投入資源。也許你可以專注流程中那些「非顯眼但至關重要」的環節,或是小而精且適場景的模型,都可能很有市場價值!